Google Cloud Next Tokyo 2017

Google Cloudが主催しているGoogle Cloud Next Tokyoというイベントが東京で開催されたので行ってきた。結構ツメツメで一つの時間帯に4,5セッションあり、全部回ることは物理的に不可能だったので、行ったやつだけレポート書いておく。
キーとなるテーマは「働き方」という話ではあったのだが、参加したセッションが技術よりだったので「働き方」に関するレポートは薄め。後日youtubeにアップされるらしいので興味があるものはそちらで。
先に全体の感想を書くが、container化がさらに進みそう。
また、Datacenter as a Serviceというのが印象的。
あとビッグデータとか機械学習は変わらず力入れているっぽい。
さて、各個別のセッションについて
Day1
### 基調講演
ビッグタイトルが並ぶが、GCPの活用事例の紹介。
Pokemon Go
有名な話。想定の50倍以上のトラフィックでもオートスケールして耐えた。
SnapChat
アメリカ発スタートアップ。チャットアプリ。結構有名なんじゃないかなと。
小規模のスタートアップでもアプリの作成に注力してユーザーに価値を届けられる。
HSBC
金融システムのクラウド移行の事例。
3兆円分くらいあるアセットの管理をクラウド上で行う。
ファミマ
試験導入が行われたらしい。
店舗間のコミュニケーションや機械学習を用いた在庫管理等。
マリオラン
任天堂・DeNA・Googleが作ったゲーム。
150ヶ国で展開。GAEベースで作られているとのこと。
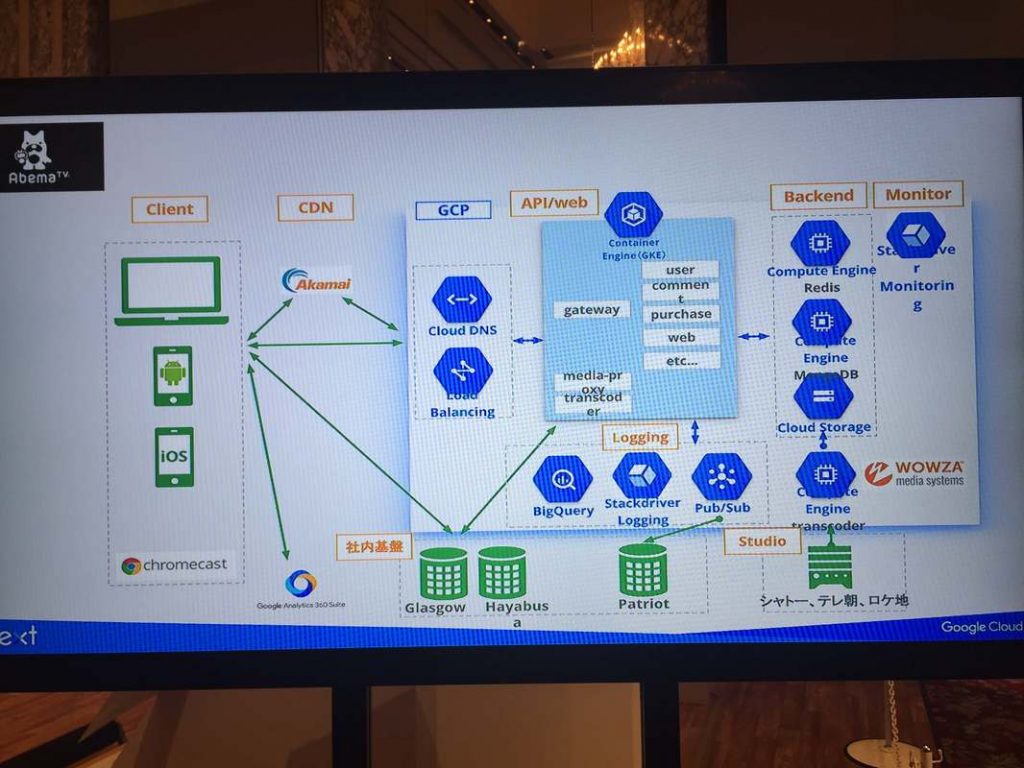
(アーキテクチャ図が公開されていたので末尾に貼っておく)
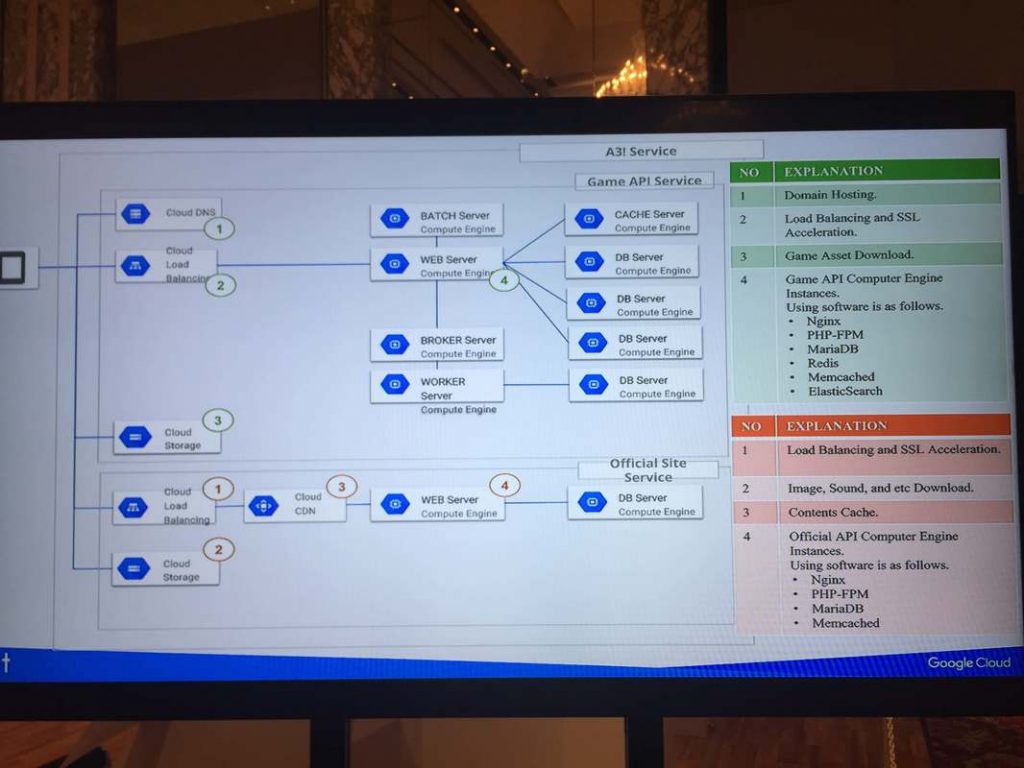
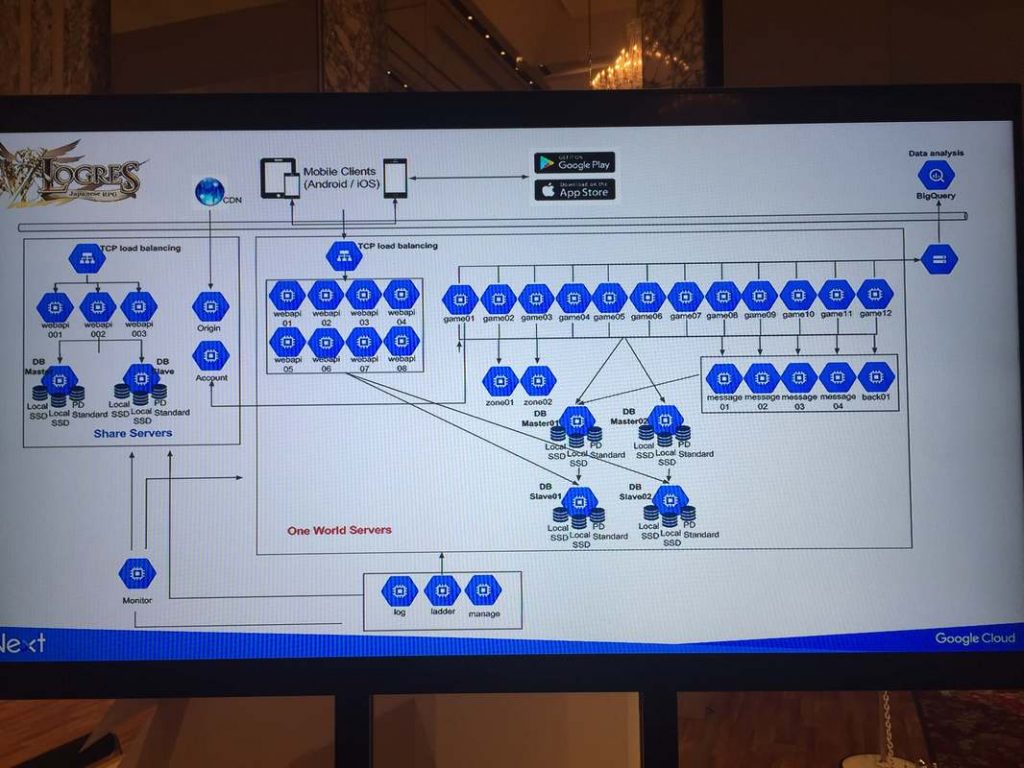
メルカリ
フルGAEで構築。あんまり覚えてない。
(こちらもアーキテクチャ図が公開されていたので末尾に貼っておく)
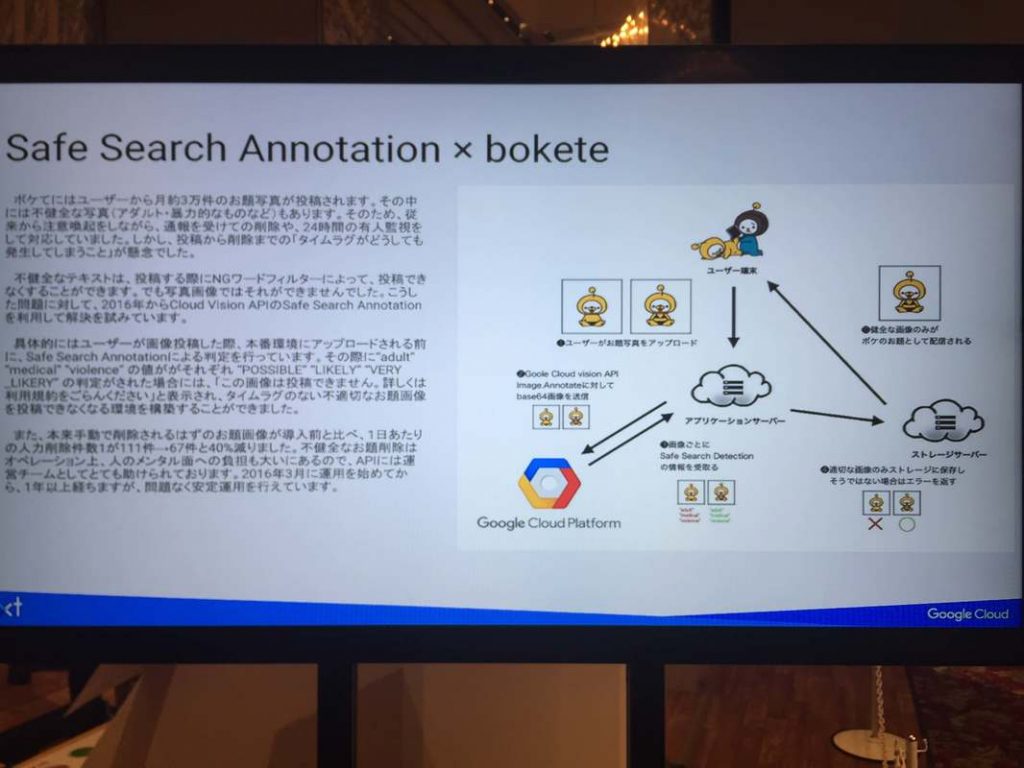
順序が前後するが、セキュリティの観点からDLP(DataLossProtection?)の話が出てくる。
何をやるかというと、機械学習によって学習したパターンを使って顧客情報のマスキングを行う。
例えば顧客対応中に取得したクレカ情報や、マイナンバーの画像などをDLPを通すことにより
マスキングして社内の保存するために使ったりするらしい。
Softbank, KDDIとの協業の話が出てた。
### 12:00 – 12:40 事例から学ぶ機械学習のいま
福岡の株式会社グルーブノーツの話。
MAGELLAN BLOCKSという製品を開発しておりそれの活用事例。
機械学習は難しい。機械学習の専門知識と顧客のビジネスに対する専門知識の掛け算だからだ。
機械学習の専門知識を不要とし、顧客は自らのビジネスの専門知識を使って機械学習を効率よく使いましょう。
というコンテキスト。
GCPの上で稼働しておりブロックを繋げていくことにより独自のAPIを作ることが可能。なデモがあった。
I/Oとしてはgcsやsalesforceへのデータ流し込みができたりするらしい。
ブロックの中にはgoogleの学習済みの画像解析とか言語処理とか使うことができる。
個人的なへぇと思ったのは、画像等を0から学習させるのはかなりの点数がいるが、
数値ベースの学習であればサンプル数は1000くらいでもかなりの精度を出す。という話。
### 13:00 – 13:40 Google Container Engine 入門 : ヒントとベスト プラクティス
kubernetesの概要についてだった。公式のdocumentを読んだ方が理解が早いかもしれない。
Google Container Engineはkubernetesのホストマネージドサービス。
- pod
- deployment
- service
- node
の簡易的な説明とデモ。この4つを理解するのがまずはいいんじゃないかとのこと。
Cluster自身のAutoscalerがβ版で搭載されている。
kubernetes dashboard見やすいよ。(GUIツール)
というtipsも話してくれた。
### 14:05 – 14:45 「どこでコードを走らせるべきか ?」Compute Engine / Container Engine / App Engine / etc
GCE
- 既存システムの代替として
- 特定のOS/kernelを使いたい時
- HTTP/Sではないプロトコルを利用したい時
- インフラ周りのUPDATEを自分でコントロールしたい
こんなときに最適。あとリソースの配分がかなりフレキシブルで1core 455GiメモリのVMとかも作れるらしい。
GKE
アプリケーションの管理の方法を大きく変えるだろう。
インフラからの断絶ができる。
kubernetesのマスタはGKEが管理する。(フルマネージド)
GAE
実質運用オペレーター0人でいける
スケールアップ・ダウンが高速
安全なロールアウトやA/Bテストのトラフィック分割とかしてくれる。
言語縛りがあるPython, Go, Ruby, PHP。
HTTP/Sのみ。
Cloud Function
いわゆる server less。
pub/sub, cloud storageのhook, http requestで動く。
nodejsのみ。
データ変換とかイベントドリブンで動くものに最適。
それぞれ抽象化したいものが異なるので最適な選択を。
### 15:10 – 15:50 Cloud Site Reliability Engineering(SRE): お客様へのインパクト
GCPのインフラに強く、可用性と開発に関与。
頑張って世話役になってね。
- 信頼性
- 拡張性
- パフォーマンスにフォーカスしている。
SLA
サービスレベルアグリーメント
これは契約上の話なので必達目標として頑張る
SLO
サービスレベルオブジェクティブ
目標レベル。もちろん SLO>SLA。
やることは
- 可用性
- レイテンシ
- 効率性
- 変更管理
- 監視
- 緊急対応
- キャパシティプランニング
あたりに責務があり、アクションを取っていく。
Google側でもセールスサポート・監視・テクニカルソリューションでサポートがある。
あと、GoogleがEbookとして出している
http://landing.google.com/sre/book.html
これ一人もらってた。
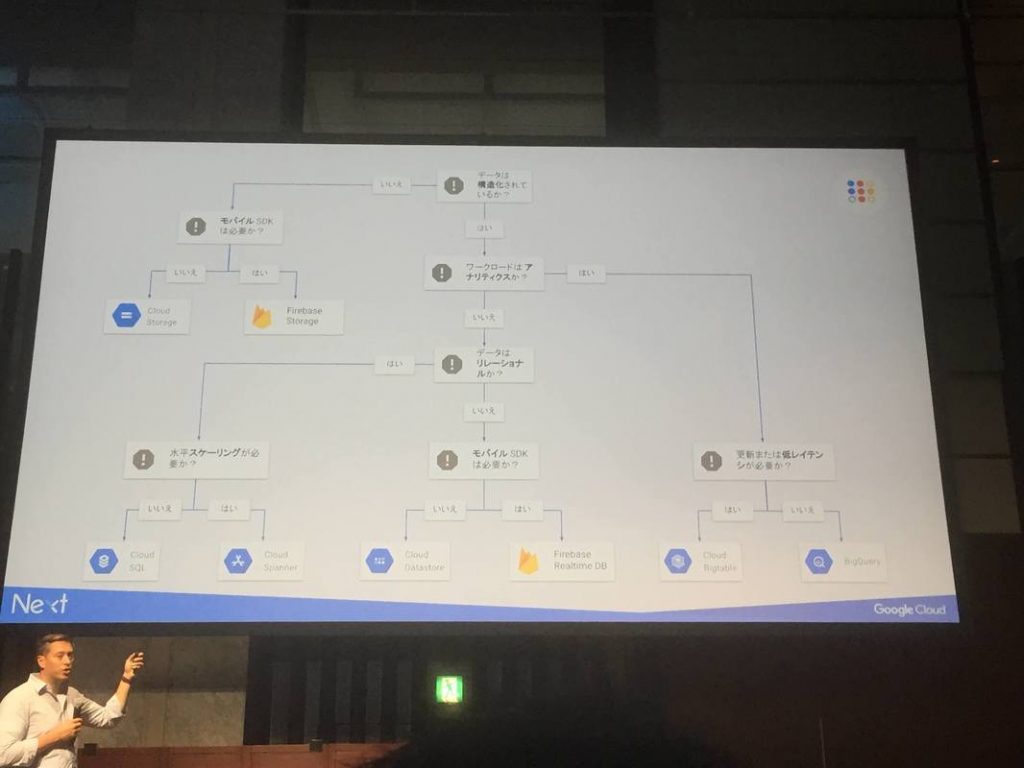
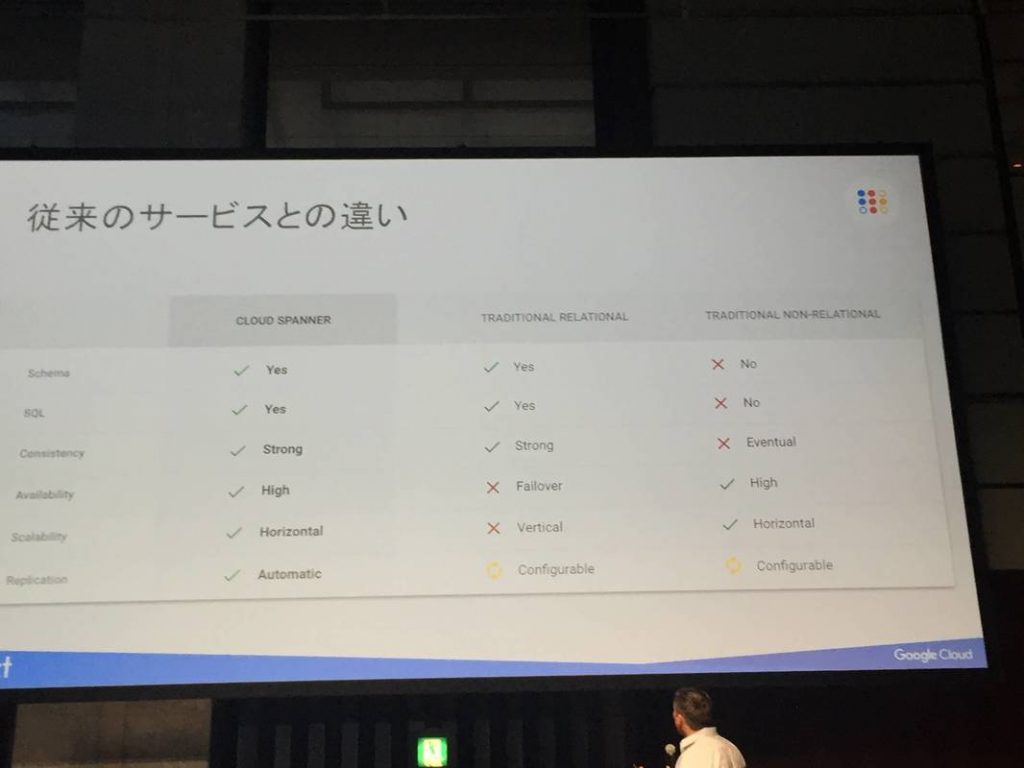
### 16:15 – 16:55 Cloud Spanner 入門
最近盛り上がっているSpannnerの紹介。
SpannerのGoalは
- 水平スケール
- グローバル ACIDトランザクション
- No Downtime
とのこと。これらをフルマネージドで提供する。
利点は
- これまでのリレーショナルセマンティクスの利用が可能(ACID、スキーマetc)
- リージョン内外をまたぐレプリケーションによる可用性
標準SQL、アクセス管理、ログ管理、
java,python、go,node等のclient libの充実、
JDBC
など結構力入れているみたい。
(googleが必要だったから作ったので力入れるとか入れないとかなさそうだけど)
あとはdocumentを読んだ方が早そうだが、紹介されていた昨日は
インターリーブテーブル
has_manyの関係にあるレコードを一緒に含めて持たせる。
ようなイメージだった。(詳しくは把握していないのでdocument参照)
### 17:20 – 18:00 プリンシパル・ソフトウェアエンジニアが語る Google のネットワークインフラ技術
二日間の中で最も難しかった。が、一番面白そうだった。
全然理解できていないのでレポートも何もあったもんじゃないのだが。
(後日youtubeに上がったら見直す)
googleが開発したネットワークについての詳細な話。
- データセンター内のネットワーク
- データセンター間のネットワーク
- データセンターと外を結ぶネットワーク
これらの話をしていた。
データセンター内でもレイテンシが違う(ラック内、ラック間とか距離とかで)のが困る。
とか、
汎用ネットワークスイッチだと対応できないから自ら作った「jupiter」の話。
とか、
Closトポロジーで貼るメッシュネットワークの話とか。
修行してまた出直します。
以上Day1。
余談だが、会場のキャパと動線が辛い感じで後から頑張って修復していた。
海外とかだと会場が広く外に出たりしてリフレッシュとかもできるのだろうけど、
地下のコの字型の空間で人の流れが詰まる。休憩時間内に移動しきれないとか不思議だった。
Day2
### 基調講演
二日目はだいぶ開発よりな視点から。という感想。
オープンさ
OPEN DEVELOPMENT = Open Source + Open API + Open Cloud
で成り立つ開かれた開発を大切にしている。
なのでgoogle企業としてもこれらのコミュニティに対して大きな貢献をしていますよとのこと。
続いてGCPの活用事例。
KARTEというサービスを開発しているプレイドという企業。
スタートアップで基調講演出るのがすごい。
やっている内容も面白かった。オンライン接客。
ECサイト等に訪れた顧客情報を管理して、管理画面上で来店回数や名前とかを確認できるようなUIの紹介があった。
裏はBigQueryとBigTableを利用しているとのこと。
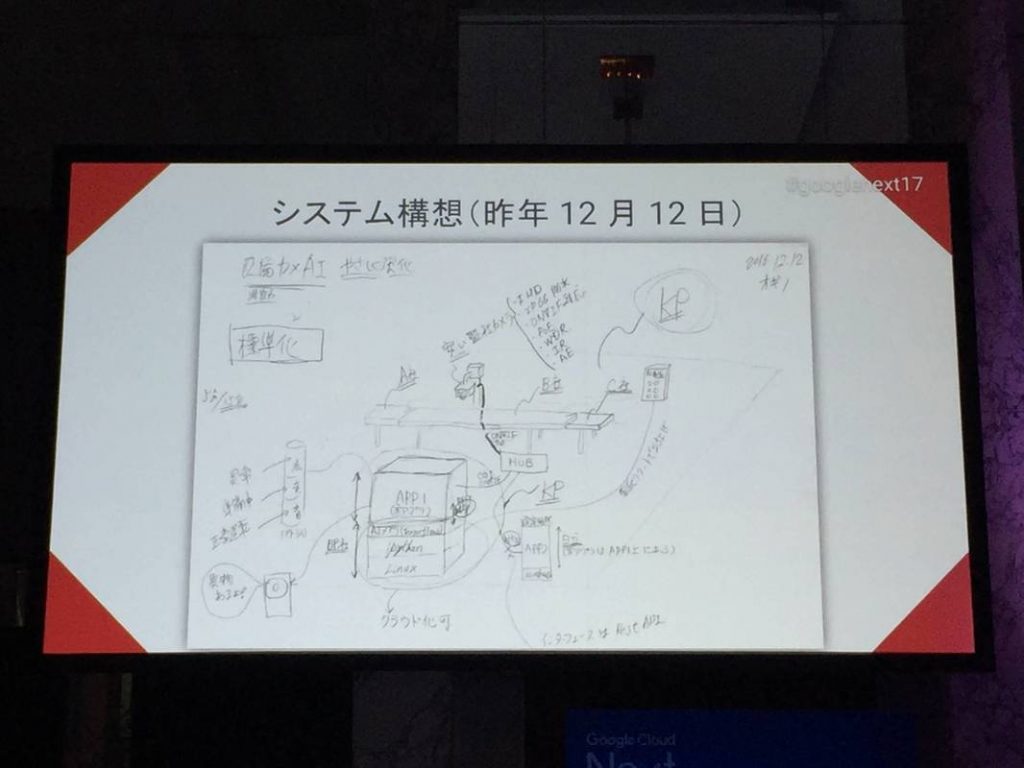
次はマヨネーズのキューピー。
不良品の検知に機械学習を利用した事例が紹介されていた。
また試作品のラフ絵みたいなのが共有されていたので末尾に貼っておく。
最後はSony。
ちょっと聞き取りづらくてあんまり話が頭に入ってこなかった。
youtubeを見ていただければ。
### 12:00 – 12:40 AI /マルチクラウド時代の働き方改革
KDDIが話す働き方改革。
結局多くの企業が働き方を変えないといけない、労働時間とか規制が厳しくなってきている。
しかし、やり方がわからない。なので2016年の調査結果でもやっている施策No.1が「ノー残業デー」とか。
なのでアジャイルをがっつり組織に組み込んでみました。最初は1チームから。
部署として認めてもらうのに3年かかった。
ただ、これをやることによりイノベーションの種が育ちやすくなった。
今はKDDIアジャイル開発センターというのが作られたらしい。
また会議も不要なものが多すぎる。
解決策の一つとしてCISCOの専用テレビの紹介がされていた。
### 13:00 – 13:40 Google Cloud Dataflow で実現するストリームおよびバッチデータ処理
DataflowはApache BeamとしてOSS化されている。
事例紹介として、cobanというサービスを展開しているLastRoots社の話。
cobanは「みるとビットコインがもらえる広告」みたい。
使っている技術はCloud Dataflow、firebase、BigQuery。
Dataflowで
広告の最後に出てくる「コバン」を押された数(金額に関わるっぽい)の集計
を行って、広告主側にタイムリーに表示する。という箇所とのこと。
ここもスタートアップらしい。面白いサービス考えるなーという感想。
### 14:05 – 14:45 BigQuery と Cloud Machine Learning : 大規模ニューラル ネットワークによる予測
BigQuery
1Pbpsというネットワークの元に構築されていて、
おそらく同様のサービスを実装できたとしてもそこまで性能を出すことはできない。
とは言っていた。
通常のselect以外にも特別なものとしては特徴量検索も行うことができる。
ある複数のワードに関連するものを見つけることができる機能。
stack overflowの記事の中から該当のキーワードに最も関連の高いものを出す。
といったデモが行われていた。
またUser Defined Function(UDF)も使いやすいからオススメとのこと。
ML Engine
googleが提供する機械学習には「トレーニング済みMLモデル」「カスタムMLモデル」の二つがある。
ML Engineは後者のカスタムMLモデル用。
いわばフルマネージドTensorFlow。
アメリカのマンハッタンの位置を学習して、経度緯度をinputするとマンハッタン内なのかどうかを判定するようなMLモデルを構築していた。
MLの前にBigQueryをもうちょいキャッチアップしたいなーという感想。
### 15:10 – 15:50 時間を有効に使うためのテクノロジーの活用方法
技術はあんまり関係なく働き方の啓蒙活動な感じ。
時間を無駄にするのは以下の6つだ。
- 中断
- 先延ばし
- ノーと言えない
- パーキンソンの法則(1時間のMTGは1時間かかる)
- 使える時間の過大評価
- 生産的な時間が確保できない
個別具体的にはyoutubeを見ていただければ。
現状だと当てはまるものは少ないが意識的に「中断」と「先延ばし」には気をつけよう。
あとエンジニアは特に「使える時間の過大評価」によって見積もりが大きく狂う可能性があるから気をつけよう。
また、単なる動機付けというのは目標達成の観点からは意味がない。
という調査結果を話ししていた。
事例としては、
運動をあまりしないグループに「動機を確認した」場合と「やる時間を宣言してもらった」場合では、
後者の方が圧倒的にそのグループは運動を行った。という話。
スケジューリングとか計画って大事だなと。
最後は、他人のフォーカスタイムを邪魔するな。
それは文化とか環境に依存するけどそういう空気作りが大切。とのこと。
### 16:15 – 16:55 Google Cloud Functions と Firebase によるバックエンド サービスの拡張
FirebaseでSDK入れて、Cloud Functionを使ってサーバーサイド実装すると、
バックエンドサービスも含めて簡単に作れるよ。のデモだった。
Cloud Functionはnode。
Firebaseに関して深く突っ込んでいる訳でもなく、
Cloud Functionがrequestに対して反応するjobだという理解をしているので、
それ以外には特に目立った発見はなかった。
### 17:20 – 18:00 Google Cloud Platform におけるコンテナ アプリ開発概論
前述したGoogle Container Engine入門の具体例。
- アプリ作って
- Dockerfile作って
- docker runして確認して
- gcrに入れて
- kubernetes runでそのimageを呼び出して
- ブラウザから確認できるよね
という超高速のデモ。cloud shellはテストをしたりするのはとても楽そう。
またHelmの紹介があった。redisをgkeクラスタ内に瞬殺で立てている様子が見られた。
まだ使ったことのないものなので後日遊んでみることにする。
### 18:00 – 19:30 Next ’17 in Tokyo Night
パーティーです。軽く写真撮ったので末尾に。
出展ブース
提携企業や体験ブースが出ていた。
印象的だったのは
- Spanner
- ラズパイでmacアドレス集計してモニタに表示したりしている会場全体の状態を数値で表したやつ
- JamBoard(電子ホワイトボードのすごいやつ)
- kubernetesのpodモグラ叩きみたいなやつ
そういやこの辺写真撮り忘れたのが失態。。。